Full parallelization in Playwright

How many workers should we setup in our config ?
How many shards should we use in our CI ?
Do we need fullyParallel true in Playwright config ? What does it even mean?
If you ever asked any of these questions, then you are in luck. Here is a way you can find your answers. Its much easier to understand things when you do them yourself, however if you are here just to quickly see the answers, then skip the setup part and go straight to results
SETUP:
Install playwright using the following command
npm init playwright@latestNow at this point. Lets write some tests with the purpose to discover ourselves how playwright will split our tests in order to achieve full parallelization. Create a file for your test (my example I named it para_1.spec.ts. Name it however you want and add this:
import { test } from "@playwright/test";
test.describe('FIRST SUITE', () => {
test("1 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("2 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("3 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("4 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
});
test.describe('SECOND SUITE', () => {
test("5 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("6 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("7 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("8 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
});We have:
- 2 Test Suites (describe block)
- Each test suite has 4 tests. A total of 8 tests in our first spec file
Pro tip: we can have a look under the hood at our configs live during the test run using this little hack, of putting testInfo as a second argumentOur second spec file, I named it para_2.spec.ts and it looks like this:
import { test } from "@playwright/test";
test.describe('full PARALLEL', () => {
test("9 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("10 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("11 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("12 parallel", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
});
It has:
- Just one test suite
- 4 Tests
Our third file, I named it serial.spec.ts . Name it as you like and add a third round of tests, that will run in SERIAL mode.
import { test } from "@playwright/test";
// this will override fullyParallel to false, only for this file
test.describe.configure({ mode: 'serial' });
test.describe('SERIAL suite', () => {
test("1 serial", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("2 serial", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("3 serial", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
test("4 serial", async ({ page }, testInfo) => {
console.log(`file.name: ${testInfo.titlePath[0]} | describe: ${testInfo.titlePath[1]} | test.name: ${testInfo.title} | worker_id :${testInfo.parallelIndex} | shard.index: ${JSON.stringify(testInfo.config.shard)}`)
});
});It has:
- Just one test suite
- 4 Tests
The little hack to run only this spec file in serial mode I am going to elaborate on a different post but for now, the comment above it, is enough explanation to understand.
Now lets configure our playwright to use full parallelization
Inside our playwright.config.ts file you should have like this
import { defineConfig, devices } from '@playwright/test';
export default defineConfig({
testDir: './tests',
/* Run tests in files in parallel */
fullyParallel: true,
workers: process.env.CI ? 3 : 1,
/* Reporter to use. See https://playwright.dev/docs/test-reporters */
reporter: 'html',
projects: [
{
name: 'x',
use: { ...devices['Desktop Chrome'] },
}
],
});As you notice this config file has the bare minimum to run, because we are only interested in particular settings. The rest of the config values are up to you how to make them, but for those above let me explain:
workers: process.env.CI ? 3 : 1 if we are in CI it will setup to run using 3 workers, if not it will run with 1 worker. Config this as per your limitations. Remember that number of workers will increase the load on the CPU of your machine. So you know best what works on your local machine and how powerful your CI runners are.
fullyParallel: true means that this will spawn workers and have spec files assigned to them, but also the test suites (describe blocks) are mixed, and... wait for it... the tests inside are also mixed. So you would have for example the same worker running second test from suite 1 of spec file 1 and then after it will finish will do third test from suite 1 of spec file 2. This is what it means full parallelization, work is balanced not just per spec file, but also per describe block and even per tests.
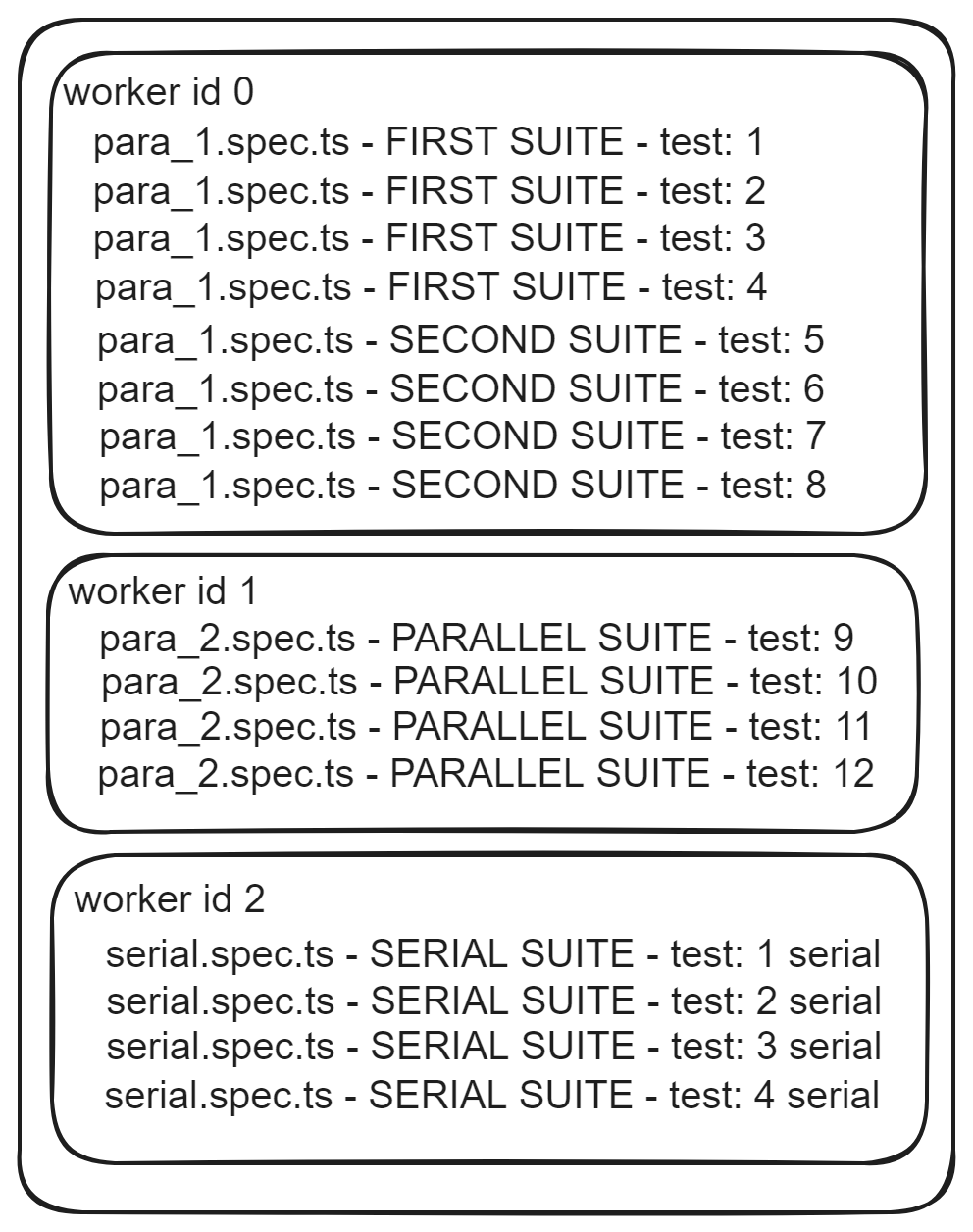
RESULTS:
See below an example of a result using parallelization
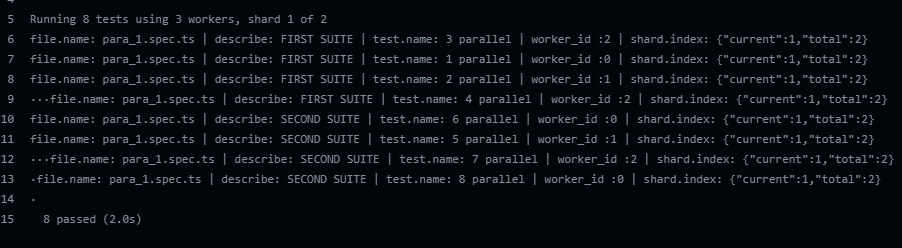
I have setup in my CI to run using two shards (machines), above you see the results for our first machine. See below the results for our second machine, in other words from shard index two:
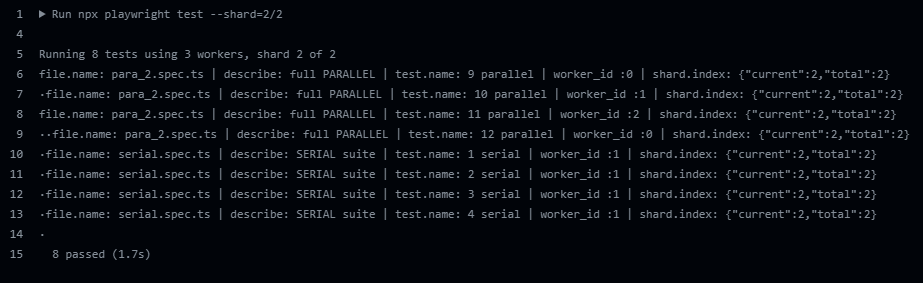
Besides full parallelization, when you are running in CI, you can balance the load on multiple machines using sharding.
Here is a visual representation of our first machine

And here is a visual representation of our second machine:
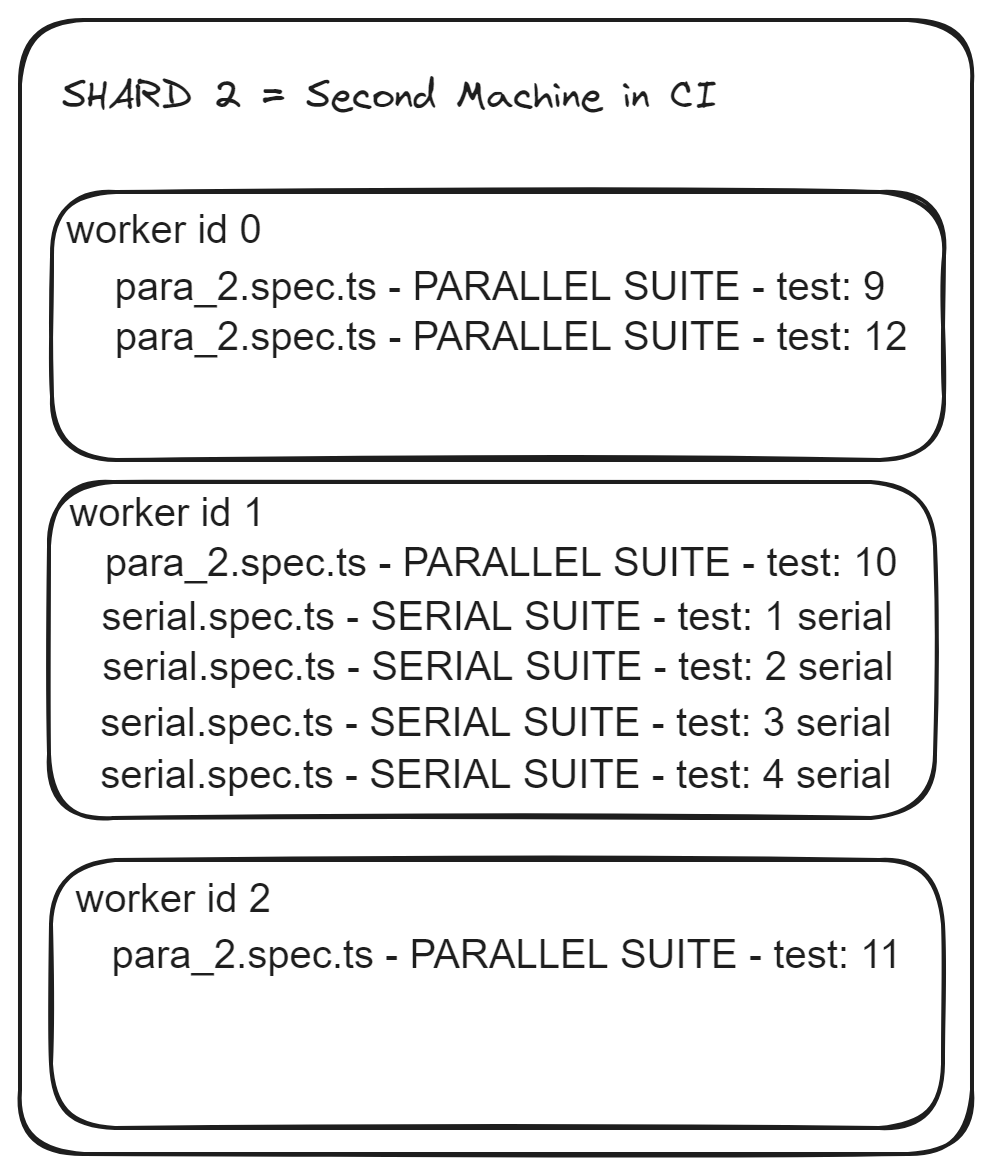
We have to pay attention here at worker id 1 . Notice how :
- It is mixed between para_2 file and serial file
- The whole suite from serial file and all tests are in the same worker
- Tests run in order 1 2 3 4
Now look at worker id 2, that it has just 1 test from one spec file. If our serial spec file would have been in parallel mode we would have not have such inefficient load balancing. From Playwright point of view, because serial.spec.ts file was in serial mode, it considered all of it as a whole and it did not try to split the tests, only the spec files got balanced.
You can see the explanation here, that even if you don't have fullyParallel set to true, it will still run in parallel but it will not be as they call it FULL parallel mode, because they perform load balancing at spec level. If you want more granular than that, you have to enable it.
Just for the fun of it. See below RESULTS for a normal setup without sharding or fullyParallel turned on. But still with 3 workers on just one machine:
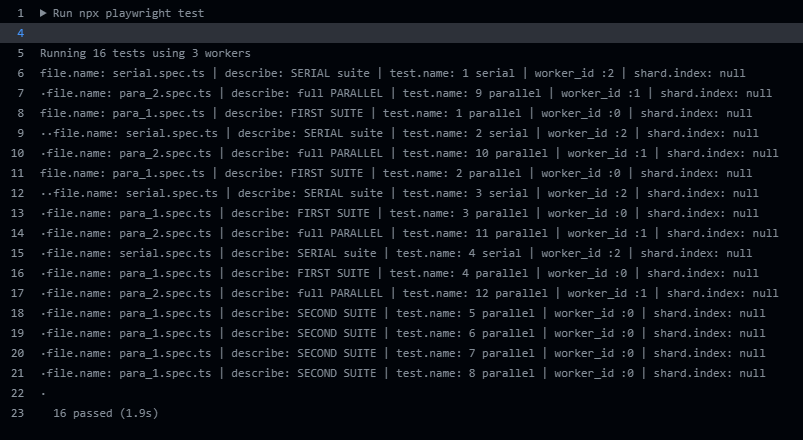
Here is the visual representation:
It split the spec files only. It ran in parallel with 3 workers indeed. And it ran in order.
Its safe to say that this is not ideal, and most likely will cost you time and we all know that time is money.
But what about the workers? How would I know how many workers my setup can handle? Well, Butch Mayhew, explains here a way that you can test your environments and find out what are the optimal values to choose.
What about sharding? How many machines should I choose? Well the answer depends on your own setup, not everybody has access to the same resources. Here are a few factors you have to take in consideration when you decide on a number:
- A new machine (use of sharding) means a new instance means more costs
- Sometimes on some projects when you spin up a machine the setup to get everything up and running for the tests to execute takes a long time. Its a trade off you have to consider
- A machine can have a certain capacity on its CPU so overloading one machine with multiple workers may be more heavier than just having more machines with less workers for each.
Hit the clap button if you found this useful. Or even buy me a coffee if you want to motivate me even more.



Comments ()